foreach
- Only access
当使用foreach循环基本类型时变量时不能修改集合中的元素的值,遍历对象时可以修改对象的属性的值,但是不能修改对象的引用
- Only single structure
同时只能遍历一个collection或数组,不能同时遍历多余一个collection或数组
- Only single element
遍历过程中,collection或数组中同时只有一个元素可见,即只有“当前遍历到的元素”可见,而前一个或后一个元素是不可见的。
- Only forward
只能正向遍历,不能反向遍历
- At least Java 5
如果要兼容Java 5之前的Java版本,就不能使用For-each
- Iterable
任何一个集合,无论是JDK提供的还是自己写的,只要想使用foreach循环遍历,就必须正确地实现Iterable接口
- Array
Java将对于数组的foreach循环转换为对于这个数组每一个的循环引用。
正则
- 匹配的模式(Pattern flags)
Pattern Pattern.compile(String regex, int flag)
| 编译标志 | 效果 |
|---|---|
| Pattern.UNIX_LINES | 启用 Unix 行模式。在此模式中,.、^ 和 $ 的行为中仅识别 ‘/n’行结束符。通过嵌入式标志表达式 (?d) 也可以启用 Unix 行模式。 |
| CASE_INSENSITIVE | 启用不区分大小写的匹配。默认情况下,不区分大小写的匹配假定仅匹配 US-ASCII 字符集中的字符。可以通过指定#UNICODE_CASE标志连同此标志来启用 Unicode 感知的、不区分大小写的匹配。通过嵌入式标志表达式 (?i)也可以启用不区分大小写的匹配。指定此标志可能对性能产生一些影响。 |
| COMMENTS | 模式中允许空白和注释。此模式将忽略空白和在结束行之前以 #开头的嵌入式注释。通过嵌入式标志表达式 (?x) 也可以启用注释模式。 |
| MULTILINE | 启用多行模式。在多行模式中,表达式 ^ 和 $仅分别在行结束符前后匹配,或者在输入序列的结尾处匹配。默认情况下,这些表达式仅在整个输入序列的开头和结尾处匹配。通过嵌入式标志表达式 (?m) 也可以启用多行模式。 |
| LITERAL | 启用模式的字面值解析。指定此标志后,指定模式的输入字符串就会作为字面值字符序列来对待。输入序列中的元字符或转义序列不具有任何特殊意义。标志 CASE_INSENSITIVE 和 UNICODE_CASE 在与此标志一起使用时将对匹配产生影响。其他标志都变得多余了。不存在可以启用字面值解析的嵌入式标志字符。 |
| DOTALL | 启用 dotall 模式。在 dotall 模式中,表达式 .可以匹配任何字符,包括行结束符。默认情况下,此表达式不匹配行结束符。通过嵌入式标志表达式 (?s) 也可以启用 dotall 模式(s 是 “single-line” 模式的助记符,在 Perl 中也使用它)。 |
| UNICODE_CASE | 启用 Unicode 感知的大小写折叠。指定此标志后,由 #CASE_INSENSITIVE标志启用时,不区分大小写的匹配将以符合 Unicode Standard的方式完成。默认情况下,不区分大小写的匹配假定仅匹配 US-ASCII 字符集中的字符。通过嵌入式标志表达式 (?u)也可以启用 Unicode 感知的大小写折叠。指定此标志可能对性能产生影响。 |
| CANON_EQ | 启用规范等价。指定此标志后,当且仅当其完整规范分解匹配时,两个字符才可视为匹配。例如,当指定此标志时,表达式 “a/u030A” 将与字符串 “/u00E5”匹配。默认情况下,匹配不考虑采用规范等价。不存在可以启用规范等价的嵌入式标志字符。指定此标志可能对性能产生影响。 |
| UNICODE_CHARACTER_CLASS | 启用Unicode版本的预定义字符类和POSIX字符类。当这个标志被指定时,那么(仅US-ASCII)预定义的字符类和POSIX字符类符合Unicode技术标准#18:Unicode正则表达式;附录C:兼容性属性; UNICODE_CHARACTER_CLASS模式也可以通过嵌入标志表达式(?U)。该标志暗示着UNICODE_CASE,也就是说,它启用Unicode感知的案例折叠,指定此标志可能会导致性能损失。 |
static
- 成员变量
- 成员方法
- 静态块
- 静态导包
strictfp
浮点运算更加精确,而且不会因为不同的硬件平台所执行的结果不一致的话,可以用关键字strictfp.通常处理器都各自实现浮点运算,各自专业浮点处理器为实现最高速,计算结果会和IEEE标准有细小差别。比如intel主流芯片的浮点运算,内部是80bit高精运算,只输出64bit的结果。IEEE只要求64bit精度的计算,你更精确反而导致结果不一样。所以设立‘严格浮点计算strictfp’,保证在各平台间结果一致,IEEE标准优先,性能其次;而非严格的浮点计算是“性能优先”,标准其次。
https://baike.baidu.com/item/IEEE%20754/3869922?fr=aladdin
transient
- 一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
- transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
- 被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化。
若实现的是Serializable接口,则所有的序列化将会自动进行,若实现的是Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal方法中进行手工指定所要序列化的变量,这与是否被transient修饰无关。
synchronized
- 确保线程互斥的访问同步代码;
- 保证共享变量的修改能够及时可见;
- 有效解决重排序问题.
- 偏向锁
偏向锁是Java 6之后加入的新锁,它是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁(会涉及到一些CAS操作,耗时)的代价而引入偏向锁。偏向锁的核心思想是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。所以,对于没有锁竞争的场合,偏向锁有很好的优化效果,毕竟极有可能连续多次是同一个线程申请相同的锁。但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
- 轻量级锁
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的),此时Mark Word 的结构也变为轻量级锁的结构。轻量级锁能够提升程序性能的依据是“对绝大部分的锁,在整个同步周期内都不存在竞争”,注意这是经验数据。需要了解的是,轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。
- 自旋锁
轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。这是基于在大多数情况下,线程持有锁的时间都不会太长,如果直接挂起操作系统层面的线程可能会得不偿失,毕竟操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,因此自旋锁会假设在不久将来,当前的线程可以获得锁,因此虚拟机会让当前想要获取锁的线程做几个空循环(这也是称为自旋的原因),一般不会太久,可能是50个循环或100循环,在经过若干次循环后,如果得到锁,就顺利进入临界区。如果还不能获得锁,那就会将线程在操作系统层面挂起,这就是自旋锁的优化方式,这种方式确实也是可以提升效率的。最后没办法也就只能升级为重量级锁了。
- 锁消除
消除锁是虚拟机另外一种锁的优化,这种优化更彻底,Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的请求锁时间,如下StringBuffer的append是一个同步方法,但是在add方法中的StringBuffer属于一个局部变量,并且不会被其他线程所使用,因此StringBuffer不可能存在共享资源竞争的情景,JVM会自动将其锁消除。
- 可重入性
从互斥锁的设计上来说,当一个线程试图操作一个由其他线程持有的对象锁的临界资源时,将会处于阻塞状态,但当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁,请求将会成功,在java中synchronized是基于原子性的内部锁机制,是可重入的,因此在一个线程调用synchronized方法的同时在其方法体内部调用该对象另一个synchronized方法,也就是说一个线程得到一个对象锁后再次请求该对象锁,是允许的,这就是synchronized的可重入性。
volatile
参考1 就是要你懂 Java 中 volatile 关键字实现原理
参考2 volatile关键字与Java内存模型(JMM)
- 汇编指令会多出Lock前缀
将当前处理器缓存行的数据写回主存;
令其他CPU里缓存该内存地址的数据无效; - 针对编译器重排序
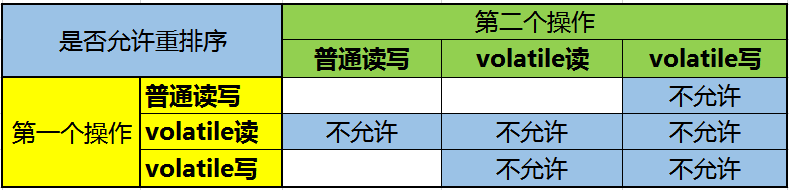
- 针对处理器重排序
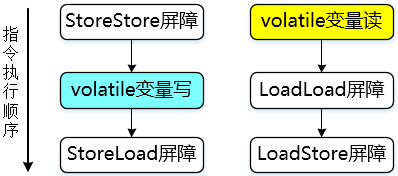
- 在每个volatile变量写操作之前插入StoreStore屏障,之后插入StoreLoad屏障;
之前插入StoreStore屏障:禁止volatile写之前的写操作与其重排序,保证之前的所有写操作都写回主存,对volatile写可见;
之后插入StoreLoad屏障:禁止volatile写之后的读写操作与其重排序,实现volatile写结果对后续操作可见;
+在每个volatile变量读操作之后,接连插入LoadLoad屏障,LoadStore屏障;
插入LoadLoad屏障:禁止volatile变量读之后的读操作与其重排序;
插入LoadStore屏障:禁止volatile变量读之后的写操作与其重排序;
通过插入两次内存屏障,实现volatile读结果对后续操作可见;
volatile用来修饰共享变量(成员变量,static变量)表明:
volatile变量写:
- 当写一个volatile变量时,JMM会把所有线程本地内存的对应变量副本刷新回主存;(注意是所有共享变量,不是一个volatile变量)
- volatile写和解锁内存语义相同;
volatile变量读:
- 当读一个volatile变量时,JMM会设置该线程的volatile变量副本(本地内存中)无效,线程只能从主存中读取该变量;
- 保证了volatile变量读,总能看见对该volatile变量最后的修改;
- volatile变量读和加锁内存语义相同;