引用参考文档链接
Java官方学习手册-Stream GitHub-CarpenterLee-JavaLambdaInternals Oracle关于parallelism官方文档 Oracle关于Stream包官方描述文档
StreamAPI 入门
Stream API 是关于向 JDK 提供众所周知的 map-filter-reduce 算法的实现
map只会变更对象的类型,不会改变对象集合的数量filter只会改变对象集合的数量,而不会改变其中对象的类型reduce允许针对数据流构建任何你想构建的数据结构
案例 - 统计所有人口超过10w的城市人口总和 城市类定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class City { public City (String name, int population) { this .name = name; this .population = population; } private String name; private int population; public String getName () { return name; } public void setName (String name) { this .name = name; } public int getPopulation () { return population; } public void setPopulation (int population) { this .population = population; } @Override public String toString () { return "City{" + "name='" + name + '\'' + ", population=" + population + '}' ; } }
数据初始化 1 2 3 4 5 6 7 8 9 10 11 List<City> cities = new ArrayList <>(); City city1 = new City ("1" , 50_000 );City city2 = new City ("2" , 2_100_000 );City city3 = new City ("3" , 90_000 );City city4 = new City ("4" , 130_000 );City city5 = new City ("5" , 1_000_000 );cities.add(city1); cities.add(city2); cities.add(city3); cities.add(city4); cities.add(city5);
普通写法 1 2 3 4 5 6 7 8 int sum = 0 ;for (City city : cities) { int population = city.getPopulation(); if (population > 100_000 ) { sum += population; } } System.out.println("Sum = " + sum);
StreamApi写法 1 2 3 4 5 6 7 8 9 int sum = cities.stream() .mapToInt(City::getPopulation) .filter(population -> population > 100_000 ) .sum(); System.out.println("Stream Sum = " + sum);
基础 流的创建 创建一个空流 一般场景不会用到,通常与flatMap结合使用,过滤不需要的元素
从可变参数或数组创建流 1 2 Stream.of(1 , 2 , 3 ) Arrays.stream(array)
给定规则创建流并持续添加元素 1 2 3 Stream.generate(Supplier<T> s) Stream.generate(() -> "test" )
需注意的是,该方法将会无限制的添加元素进入流中,需要搭配limit使用,避免OOM
创建符合一定规则的流 1 2 3 4 5 6 7 8 9 10 Stream.iterate(final T seed, final UnaryOperator<T> f) Stream.iterate("+" , s -> s + "+" )
通常需要搭配limit使用,Java9该方法添加了重载,添加了入参,可自定义停止创建规则,当规则符合false则停止创建流
1 Stream.iterate("+" , s -> s.length() <= 5 , s -> s + "+" )
创建一个在一定范围的数字流 1 2 3 4 IntStream.range(0 ,10 ); IntStream.rangeClosed(0 ,10 )
创建随机数流 1 2 3 4 5 6 7 Random random = new Random (10L );random.ints(); random.ints(10 ); random.ints(0 , 7 ); random.ints(10 , 2 , 9 );
相对应的,还有long与double
通过String创建char字符流 1 2 String test = "test" ;IntStream chars = test.chars();
读取文件创建流 1 2 3 4 5 6 7 8 9 10 11 Path log = Path.of("/tmp/debug.log" );try (Stream<String> lines = Files.lines(log)) { long warnings = lines.filter(line -> line.contains("WARNING" )) .count(); System.out.println("Number of warnings = " + warnings); } catch (IOException e) { }
通过正则创建流 1 2 3 4 String sentence = "For there is good news yet to hear and fine things to be seen" ;Pattern pattern = Pattern.compile(" " );Stream<String> stream = pattern.splitAsStream(sentence);
通过Builder创建流 1 2 3 4 5 6 7 8 Stream.Builder<String> builder = Stream.<String>builder(); builder.add("one" ) .add("two" ) .add("three" ) .add("four" ); Stream<String> stream = builder.build();
常用方法及功能描述 Stream
方法
功能
filter
根据用户自定义条件过滤Stream中所有数据,符合条件的通过
map
使用用户自定义的功能代码应用到每一个元素,常规用于类型转换
mapToInt
通过用户自定义的代码将当前Stream转换为IntStream(通常是为了调用IntStream额外的接口,如sum)
mapToLong
通过用户自定义代码将当前Stream转换为LongStream
mapToDouble
通过用户自定义代码将当前Stream转换为DoublegStream
flatMap
将Stream中的多维元素降一维,如Stream<List<City>>转换为Stream<City>
flatMapToInt
效果同flatMap,仅可用于int类型,如 Stream<int[]> 转换为 Stream<int>
flatMapToLong
效果同 flatMapToInt ,类型限制为long
flatMapToDouble
效果同flatMapToInt,类型限制为double
distinct
对数据流进行去重,重复判定由Object.equals(Object)确认
sorted
将流中元素根据用户实现Comparable内容进行自然排序,若类型未实现该接口,则抛出异常java.lang.ClassCastException
sorted(Comparator<? super T> comparator)
重载函数,根据入参的自定义规则进行自然排序
peek
使用用户自定义操作应用到流中每一个元素
limit
根据用户自定义长度,对流进行截断
skip
从流开头跳过用户给定长度,如果流元素数不够,则流将会被清空
forEach
将用户自定义操作应用到流中每一个元素
forEachOrdered
通常在parallel stream中使用,对流按照给定顺序进行元素操作
toArray
将流中元素组成数组返回,返回Object[]
toArray(IntFunction<A[]> generator)
重载函数,可由用户指定数组类型,使用方式toArray(String[]::new)
min/max
根据自定义的Comparator实现,寻找流中最小/最大元素
count
统计流中元素数量
anyMatch
根据用户自定义判断条件,判断流中是否有任意符合元素
allMatch
判断流中元素是否全部符合自定义条件
noneMatch
判断流中元素是否全部不符合自定义条件
findFirst
返回流中第一个元素,parallelStream中将无法保证根据给定顺序确认第一个
findAny
返回流中任意一个元素,Stream中始终返回第一个,parallelStream中将会任意返回
concat
将两个流合并为一个
IntStream/LongStream/DoubleStream 相对比常规Stream,此三种流额外实现几种方法
方法
功能
sum
将流中元素求和
average
求平均值
min
最小值(无需提供Comparator实现)
max
最大值(无需提供Comparator实现)
summaryStatistics
返回统计结果,包含元素个数、总和、最大值、最小值
提升 reduce reduce操作一般是处理一组数据生成一个值,上文中提及的sum/min/max/count都是reduce操作,因这些方法使用频繁,因此被单独设置一个方法以方便使用
找最大值 1 2 3 4 5 6 7 8 Stream<Integer> ints = Stream.of(2 , 8 , 1 , 5 , 3 ); Optional<Integer> optional = ints.reduce((i1, i2) -> i1 > i2 ? i1: i2); if (optional.isPresent()) { System.out.println("result = " + optional.get()); } else { System.out.println("No result could be computed" ); }
上方代码中,reduce操作通过用户自定义的规则(i1, i2) -> i1 > i2 ? i1: i2对整个流中数据进行规约(reduce),最终求得最大值
重载 1 2 3 Optional<T> reduce (BinaryOperator<T> accumulator) ; T reduce (T identity, BinaryOperator<T> accumulator) ; <U> U reduce (U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner) ;
其中,入参BinaryOperator<T> accumulator是由用户提供的函数,用于对所有元素进行操作,返回值会作为新元素添加到流中加入后续的规则应用,而该接口待实现的方法入参有两个,分别代表了当前元素与下一个元素,返回值会作为下一轮的当前元素;identity是由用户自定义,相当于在流的开头,人工添加一个元素,需注意的是,在parallel模式中,identity极有可能被重复使用,因此需要额外注意
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Integer reduce = Stream.of(2 , 8 , 1 , 5 , 3 ).parallel().reduce(9 , (i1, i2) -> { System.out.println("i1=" + i1 + " i2=" + i2); return i1 * 10 + i2; }); System.out.println("reduce with identity=" + reduce);
入参combiner仅在parallel模式中才会生效,非parallel模式的流将不会执行,而combiner的两个入参,分别是两个accumulator的执行结果,并且combiner本身的执行结果也会加入新的combiner中等待执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Integer reduce1 = Stream.of(2 , 8 , 1 , 5 , 3 ).parallel().reduce(7 , (i1, i2) -> { System.out.println("i1=" + i1 + " i2=" + i2); return i1 * 10 + i2; }, (i1, i2) -> { System.out.println("a1=" + i1 + " a2=" + i2); return i1 * 10 + i2; }); System.out.println("reduce with identity & combiner=" + reduce1);
collect 大多数业务场景都涉及模型的转换,此时,reduce将会力不从心,而collect将会完美的解决这个问题
1 List<Integer> collect = Stream.of(2 , 8 , 1 , 5 , 3 ).collect(Collectors.toList());
上述代码将int元素通过collect与Collectors转换为<List>集合,collect有重载的两个方法,分别如下所示
1 2 3 <R, A> R collect (Collector<? super T, A, R> collector) ; <R> R collect (Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner)
大多数情况下,我们都是使用Collector,因Collectors已经内置大多数使用频率较高的函数,如toList/toSet/toCollection/toMap等,其中toList/toSet最容易理解,即转为List/Set,如果想转换为其他的集合,则可以使用toCollection,在调用时,同时声明想要转换的集合即可,如:Collectors.toCollection(ArrayList::new)即是转换为ArrayList
Collectors.toMap 转换为Map稍微复杂一些,重载一共有以下三个
1 2 3 Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K > keyMapper, Function<? super T, ? extends U > valueMapper) Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K > keyMapper, Function<? super T, ? extends U > valueMapper, BinaryOperator<U> mergeFunction) Collector<T, ?, M> toMap(Function<? super T, ? extends K > keyMapper, Function<? super T, ? extends U > valueMapper, BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier)
其中keyMapper与valueMapper,是针对流中对象操作,分别处理出Map中的key与value
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 List<City> cities = new ArrayList <>(); City city1 = new City ("1" , 50_000 );City city2 = new City ("2" , 2_100_000 );City city3 = new City ("3" , 90_000 );City city4 = new City ("4" , 130_000 );City city5 = new City ("5" , 1_000_000 );cities.add(city1); cities.add(city2); cities.add(city3); cities.add(city4); cities.add(city5); Map<String, Integer> collect1 = cities.stream().collect(Collectors.toMap(City::getName, City::getPopulation)); collect1.forEach((k, v) -> System.out.println("key=" + k + " value=" + v));
Key值冲突 而在转换为Map的时候,通常会遇到Key值重复的问题,如果此时不加以特殊处理,则会导致旧值被覆盖问题,此时mergeFunction则发挥了重要的作用,入参是两个value,不是key,处理结果将作为新的value插入到Map中
1 2 3 4 5 6 7 8 9 10 11 12 13 cities.add(new City ("1" , 5 )); Map<String, Integer> collect = cities.stream().collect(Collectors.toMap(City::getName, City::getPopulation, (i1, i2) -> { System.out.println("i1=" + i1 + " i2=" + i2); return i1 + i2; })); collect.forEach((k, v) -> System.out.println("key=" + k + " value=" + v));
指定Map类型 有些场景中,我们需要使用其他Map类型,如HashTable,此时则需要mapSupplier的帮忙了,如下所示
1 2 Hashtable<String, Integer> collect2 = cities.stream().collect(Collectors.toMap(City::getName, City::getPopulation, Integer::sum, Hashtable::new ));
Collectors其他场景 Collectors.averagingInt求平均值
1 Double collect4 = cities.stream().collect(Collectors.averagingInt(City::getPopulation));
Collectors.collectingAndThen先通过第一个入参处理流,然后再通过第二个入参处理上一个处理结果
1 2 3 String collect5 = cities.stream().collect(Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparing(City::getPopulation)), e -> e.map(City::getName).orElse(null ))); System.out.println("largest city = " + collect5);
Collectors.joining将流中所有字符串拼接为String
1 2 3 4 5 6 System.out.println(Stream.of("2" , "8" , "1" , "5" , "3" ).collect(Collectors.joining())); System.out.println(Stream.of("2" , "8" , "1" , "5" , "3" ).collect(Collectors.joining("," ))); System.out.println(Stream.of("2" , "8" , "1" , "5" , "3" ).collect(Collectors.joining("," , "{" , "}" )));
Collectors.groupingBy根据自定义规则对流中数据进行分类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Map<String, List<City>> collect6 = cities.stream().collect(Collectors.groupingBy(City::getName)); collect6.forEach((k, v) -> System.out.println("key=" + k + " value=" + v)); Map<String, Long> collect7 = cities.stream().collect(Collectors.groupingBy(City::getName, Collectors.counting())); collect7.forEach((k, v) -> System.out.println("key=" + k + " value=" + v)); Hashtable<String, Long> collect8 = cities.stream().collect(Collectors.groupingBy(City::getName, Hashtable::new , Collectors.counting()));
Collectors.partitioningBy根据自定义判断规则,对流中元素进行分类,仅分为两组,通常在类似与统计及格人数之类场景使用
1 2 3 4 5 6 7 8 9 10 11 Map<Boolean, List<Integer>> collect9 = Stream.of(2 , 8 , 1 , 5 , 3 ).collect(Collectors.partitioningBy(e -> e > 5 )); collect9.forEach((k, v) -> System.out.println("key=" + k + " value=" + v)); Map<Boolean, Long> collect10 = Stream.of(2 , 8 , 1 , 5 , 3 ).collect(Collectors.partitioningBy(e -> e > 5 , Collectors.counting())); collect10.forEach((k, v) -> System.out.println("key=" + k + " value=" + v));
Collectors.summarizingInt类似于Stream中的summaryStatistics
1 2 3 IntSummaryStatistics collect11 = Stream.of(2 , 8 , 1 , 5 , 3 ).collect(Collectors.summarizingInt(e -> e));System.out.println("summarizingInt=" + collect11);
Collectors.summingInt求和
1 2 3 Integer collect12 = Stream.of(2 , 8 , 1 , 5 , 3 ).collect(Collectors.summingInt(e -> e));System.out.println("summingInt=" + collect12);
终章 Stream 不存储 Stream不存储任何对象在其中,其本身只充当管道的作用,它可以从各种数据结构、数组、生成器函数或I/O流进行数据传输
天然的函数式 对流的操作会产生结果,但不会修改其源。例如,过滤从集合中获得的 Stream 会生成一个没有过滤元素的新 Stream,而不是从源集合中删除元素。
延迟执行 许多流操作,例如过滤、映射或重复删除,可以延迟实现,从而为优化提供机会。例如,“查找具有三个连续元音的第一个字符串”不需要检查所有输入字符串。
可能无限 虽然集合的大小是有限的,但流不需要。诸如 limit(n) 或 findFirst() 之类的短路操作可以允许对无限流的计算在有限时间内完成。
消耗品 流的元素在流的生命周期中只被访问一次。像迭代器一样,必须生成一个新流来重新访问源的相同元素。
无状态(Stateless) 无状态操作,例如filter and map,在处理新元素时不保留先前看到的元素的状态——每个元素都可以独立于对其他元素的操作进行处理.仅包含无状态中间操作的管道可以单次处理,无论是顺序的还是并行的,数据缓冲最少。
有状态(stateful) 有状态的操作,例如 distinct和sorted,在处理新元素时可能会合并来自先前看到的元素的状态。
短路操作(short-circuiting) 如果在呈现无限输入时,中间操作可能会产生有限流(如limit),则它是短路的。如果一个终端操作在有无限输入时可能会在有限时间内终止,那么它就是短路的。在管道中进行短路操作是无限流处理在有限时间内正常终止的必要条件,但不是充分条件。
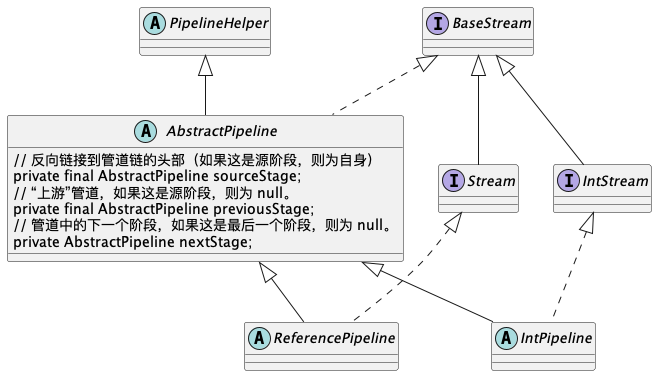
流处理过程 UML
案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 sum = cities .stream() .mapToInt(e -> { System.out.println("map:" + e.getName()); return e.getPopulation(); }) .filter(population -> { System.out.println("filter:" + population); return population > 100_000 ; }) .reduce(0 , (i1, i2) -> { System.out.println("reduce:" + i1 + " " + i2); return i1 + i2; }); System.out.println("Stream Sum = " + sum);
通过集合cities的函数stream()创建一个新的Stream,临时称作s1
s1通过函数mapToInt在自己的基础上创建一个新的Stream,临时称作s2,并将s1设置为s2的上游previousStages2通过函数filter在自己的基础上创建一个新的Stream,临时称作s3,并将s2设置为s3的上游previousStages3调用函数reduce触发结算操作,结算过程有两个核心点java.util.stream.AbstractPipeline#wrapSink通过该函数将结算操作前的所有中间操作逆序遍历(通过previousStage),生成一个从上到下的新操作链Sinkjava.util.Spliterator#forEachRemaining通过该函数将遍历数据源,并针对所有元素应用Sink(此时Sink是一条操作链,元素将会按顺序执行,直到结束或被中间操作剔除,如filter)最终返回时,在java.util.stream.ReduceOps.ReduceOp#evaluateSequential中,通过对返回结果的get()函数取出最终返回结果
中间操作的叠加与结算时操作链的生成可以通过装饰者模式去理解,而结算时downstream.accept(mapper.applyAsInt(u));可以看出,先处理自己的操作mapper.applyAsInt(u),然后再将结果传递给下一个中间操作downstream.accept1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override public final IntStream mapToInt (ToIntFunction<? super P_OUT> mapper) { Objects.requireNonNull(mapper); return new IntPipeline .StatelessOp<P_OUT>(this , StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) { @Override Sink<P_OUT> opWrapSink (int flags, Sink<Integer> sink) { return new Sink .ChainedReference<P_OUT, Integer>(sink) { @Override public void accept (P_OUT u) { downstream.accept(mapper.applyAsInt(u)); } }; } }; }
parallelStream 通过 fork/join 框架执行 Terminal操作会在java.util.stream.AbstractPipeline#evaluate(java.util.stream.TerminalOp<E_OUT,R>)中判断是否是parallel,如果是,则会通过调用ReduceTask的invoke函数执行流处理,下方堆栈是我在生成操作链是通过断点,使用Thread.currentThread().getStackTrace()得出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 = {StackTraceElement@821 } "java.lang.Thread.getStackTrace(Thread.java:1559)" 1 = {StackTraceElement@822 } "java.util.stream.AbstractPipeline.wrapSink(AbstractPipeline.java:517)" 2 = {StackTraceElement@823 } "java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)" 3 = {StackTraceElement@824 } "java.util.stream.ReduceOps$ReduceTask.doLeaf(ReduceOps.java:747)" 4 = {StackTraceElement@825 } "java.util.stream.ReduceOps$ReduceTask.doLeaf(ReduceOps.java:721)" 5 = {StackTraceElement@826 } "java.util.stream.AbstractTask.compute(AbstractTask.java:316)" 6 = {StackTraceElement@827 } "java.util.concurrent.CountedCompleter.exec(CountedCompleter.java:731)" 7 = {StackTraceElement@828 } "java.util.concurrent.ForkJoinTask.doExec$$$capture(ForkJoinTask.java:289)" 8 = {StackTraceElement@829 } "java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java)" 9 = {StackTraceElement@830 } "java.util.concurrent.ForkJoinTask.doInvoke(ForkJoinTask.java:401)" 10 = {StackTraceElement@831 } "java.util.concurrent.ForkJoinTask.invoke(ForkJoinTask.java:734)" 11 = {StackTraceElement@832 } "java.util.stream.ReduceOps$ReduceOp.evaluateParallel(ReduceOps.java:714)" 12 = {StackTraceElement@833 } "java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:233)" 13 = {StackTraceElement@834 } "java.util.stream.IntPipeline.reduce(IntPipeline.java:457)" 14 = {StackTraceElement@835 } "com.janwarlen.jdk8.stream.StreamCasesCityPopulationSum.main(StreamCasesCityPopulationSum.java:29)"
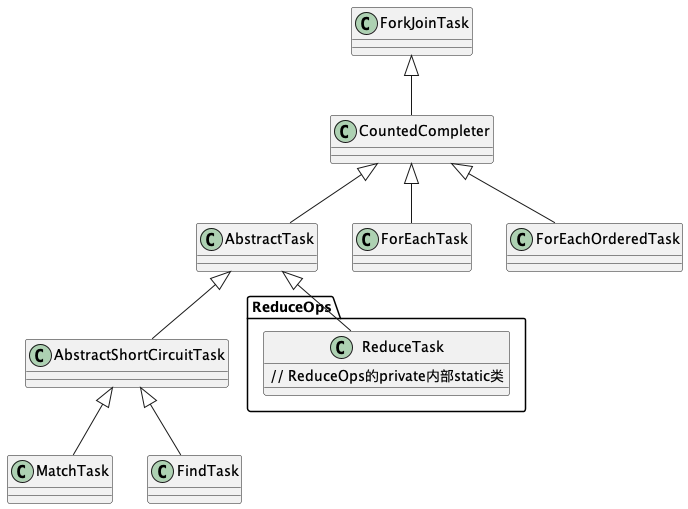
Task类继承UML 注意:并非所有parallel都是调用ReduceTask,其他类还有FindTask、ForEachOrderedTask、ForEachTask和MatchTask
自定义ForkJoinPool ParallelStreams 默认使用 ForkJoinPool.commonPool()线程池。如果需要指定线程池,可参照如下操作:
1 2 ForkJoinPool customThreadPool = new ForkJoinPool (4 );long actualTotal = customThreadPool.submit(() -> roster.parallelStream().reduce(0 , Integer::sum)).get();
注意事项
不建议将stream流操作分割为一步一步操作,这将会产生stream的临时变量,而stream对象是仅可操作一次的,这存在反复操作风险,同理也不建议作为方法函数的入参1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 List<City> cities = StreamCasesCityPopulationSum.getCities(); IntStream mapped = cities.stream().mapToInt(City::getPopulation);int all = mapped.sum();System.out.println("all=" + all); IntStream filted = mapped.filter(population -> population > 100_000 );int sum = filted.sum();all=3370000 Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed at java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203 ) at java.util.stream.IntPipeline.<init>(IntPipeline.java:91 ) at java.util.stream.IntPipeline$StatelessOp.<init>(IntPipeline.java:594 ) at java.util.stream.IntPipeline$9. <init>(IntPipeline.java:333 ) at java.util.stream.IntPipeline.filter(IntPipeline.java:332 ) at com.janwarlen.jdk8.stream.StreamAttention.main(StreamAttention.java:13 )
Stream流拆分或使用非线程安全的共享变量,则会存在数据在流处理过程中变更风险
在流处理中,尽量避免对元素的状态操作1 2 Set<Integer> seen = Collections.synchronizedSet(new HashSet <>()); stream.parallel().map(e -> { if (seen.add(e)) return 0 ; else return e; })
尽量避免Side-effects操作,如forEach/peek等,尤其是parallel模式下,可能会导致线程不安全等问题1 2 3 4 5 6 7 ArrayList<String> results = new ArrayList <>(); stream.filter(s -> pattern.matcher(s).matches()) .forEach(s -> results.add(s)); List<String>results = stream.filter(s -> pattern.matcher(s).matches()) .collect(Collectors.toList());
对顺序不敏感的流处理,可使用unordered()提高部分有状态或终端操作的并行性
仅在对顺序无感的流处理中使用parallel模式
parallel模式默认情况下公用一个线程池,因此需要避免I/O操作,以免阻塞其他并行流,或自定义一个线程池,单独提交并行流并行流中Map操作推荐使用Concurrent,如groupingByConcurrent替换groupingBy、ConcurrentMap替换Map、Collectors.toConcurrentMap替换Collectors.toMap等等,理由是在并行流中Concurrent在性能消耗方面要好很多
并行模式下避免使用有状态的lambda表达式,如下所示,与注意事项4 相同1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 List<Integer> parallelStorage = Collections.synchronizedList( new ArrayList <>()); Stream.of(1 ,2 ,3 ,4 ,5 ).parallel() .map(e -> { parallelStorage.add(e); return e; }) .forEachOrdered(e -> System.out.print(e + " " )); System.out.println(parallelStorage); List<Integer> collect13 = Stream.of(1 , 2 , 3 , 4 , 5 ).parallel().collect(Collectors.toList()); System.out.println(collect13);