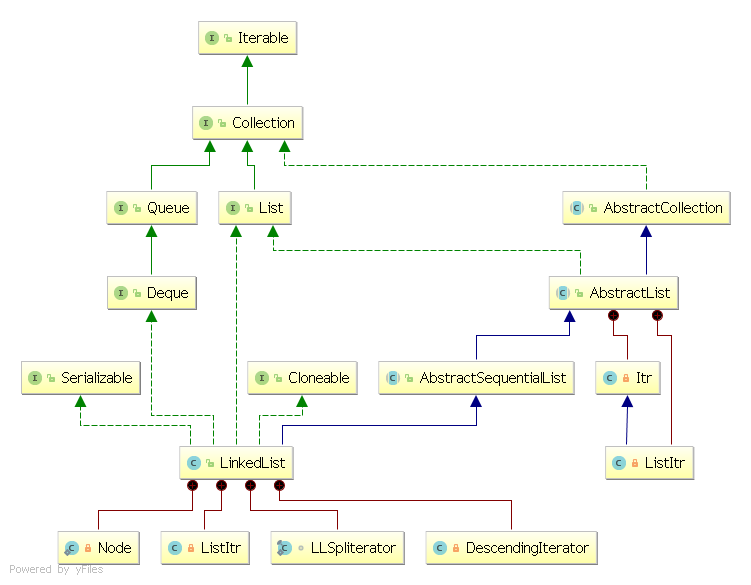
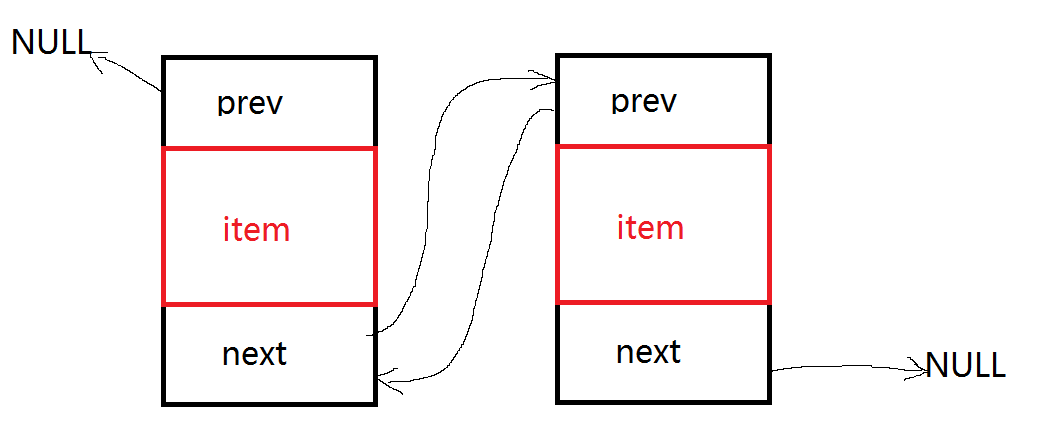
privatevoidlinkFirst(E e) { // 创建指针指向头指针指向地址 final Node<E> f = first; //创建节点,该节点next指针使用刚刚创建的指针f //即将新节点的后节点指向头结点 final Node<E> newNode = newNode<>(null, e, f); //first指针指向刚创建的节点 first = newNode;
if (f == null) //如果当前链表为空,则f将会指向null //则新节点不仅是头结点也是尾节点 last = newNode; else //因为f指向的是之前的头节点,目前的第二节点 //因此需要将节点的prev指针指向现在的头结点,完成结构搭建 f.prev = newNode; //节点数目+1 size++; //修改次数+1 modCount++; }
voidlinkLast(E e) { //创建指针指向尾指针指向地址 final Node<E> l = last; //创建新节点,新节点的前指针指向尾指针(l)指向地址 //后指针指向null final Node<E> newNode = newNode<>(l, e, null); //链表尾指针指向新节点 last = newNode;
if (l == null) //如果原链表为空,则新节点同时也是头结点 first = newNode; else //l原本指向尾节点,现在是倒数第二 //因此l指向的节点的后指针应指向新节点完成结构搭建 l.next = newNode; //节点数目+1 size++; //修改次数+1 modCount++; }
publicbooleanremove(Object o) { if (o == null) { //区分null是因为空无法使用equals函数比较 //从头结点开始,正向遍历查找 for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); returntrue; } } } else { for (Node<E> x = first; x != null; x = x.next) { //因为使用的是传入对象的equals方法进行对比,因此 //使用自定义对象的时候,建议重写equals方法 if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
//@since 1.6 //来自语言的满满恶意 //此方法有些许不同,它是删除最后一个出现的,即反向查找 publicbooleanremoveLastOccurrence(Object o) { if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { if (x.item == null) { unlink(x); returntrue; } } } else { for (Node<E> x = last; x != null; x = x.prev) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
E unlink(Node<E> x) { // assert x != null; //将待移除节点值域、指针保留,一份副本 finalEelement= x.item; final Node<E> next = x.next; final Node<E> prev = x.prev;
publicvoidclear() { // Clearing all of the links between nodes is "unnecessary", but: // - helps a generational GC if the discarded nodes inhabit // more than one generation // - is sure to free memory even if there is a reachable Iterator //理论上不用清除每一个节点的指针连接,但是这能帮助减少GC压力,因为 //丢弃的节点依然会存在内存中互相引用 //正向遍历清空每一个节点 for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } //刷新头指针与尾指针 first = last = null; //刷新链表大小 size = 0; //修改次数+1 modCount++; }
修改节点
修改指定索引节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14
//该方法虽然修改了节点 //但是并没有修改modCount public E set(int index, E element) { //校验index合法 checkElementIndex(index); //找出指定位置节点 Node<E> x = node(index); //保留一份值的副本 EoldVal= x.item; //修改节点的值 x.item = element; //返回旧值 return oldVal; }
//正向,返回第一次出现的索引 publicintindexOf(Object o) { intindex=0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; }
//反向,返回第一次出现的索引 //因为是反向查找,所以结果对于正向来说是最后一次出现 publicintlastIndexOf(Object o) { intindex= size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; }
查询指定索引节点
1 2 3 4 5
//返回值 public E get(int index) { checkElementIndex(index); return node(index).item; }